搜索到
111
篇与
哈根达斯
的结果
-
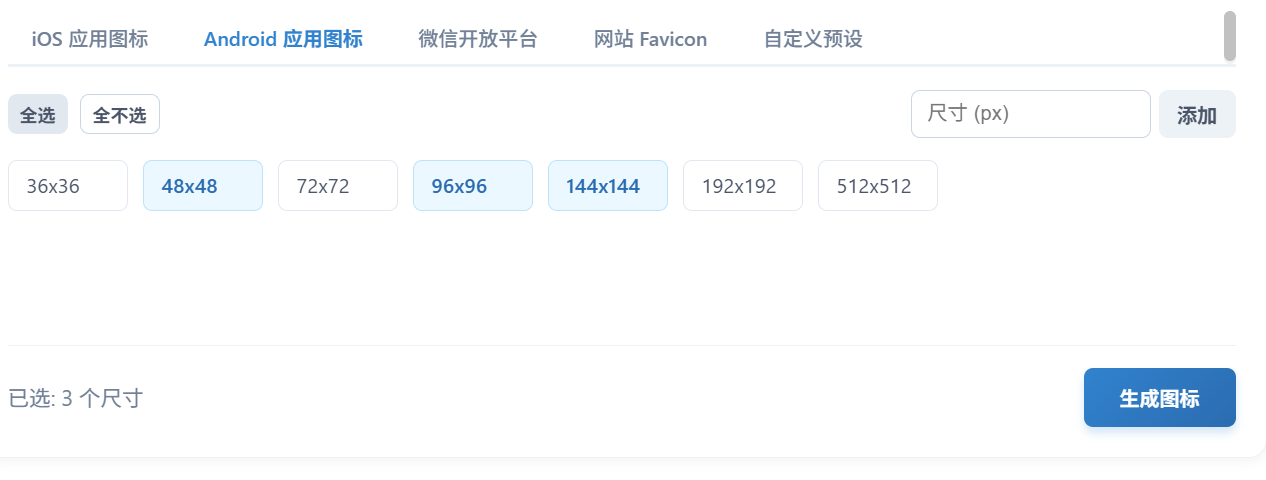
 这个图标工具,治好了我的选择困难症 这个图标工具,治好了我的选择困难症说起来,上周三下午在星巴克和几个朋友聊天,大家都在吐槽App图标制作的痛点。作为AI Native Coder,我对这个话题还挺有感触的。之前我写过一篇关于开发工具效率的文章,提到过在移动应用开发和网站建设过程中,图标制作往往是一个繁琐但必不可少的环节。不同的平台对图标的尺寸和格式都有着各自严格的要求,这让很多开发者头疼不已。我自己也深有体会。每次做新的项目,我都要花大量时间在图标上。从设计到导出不同尺寸的格式,再到适配各个平台,整个流程既繁琐又容易出错。最近我找到了一个不错的解决方案:一款在线的App图标/Favicon生成工具。我用了几次,感觉体验还不错。今天想分享一下我的使用感受。什么让我眼前一亮这个工具最吸引我的地方在于它对全平台的覆盖。我做项目经常要跨多个平台开发,需要制作不同尺寸的图标。这个工具内置了主流平台的标准图标尺寸预设,包括:iOS:iPhone, iPad, Apple Watch等全系列尺寸(20px - 1024px)。Android:适配各类分辨率屏幕的标准图标(36px - 512px)。微信小程序:覆盖小程序所需的各类图标尺寸。Web Favicon:自动生成适用于网站浏览器的.ico文件及多种PNG尺寸。这个数据还挺猛的,几乎涵盖了我平时用到的所有图标尺寸。之前我需要在PS里调整多个文件,现在只需上传一张高清原图,工具就能自动按照各平台规范进行裁剪和缩放。最让我惊喜的是实时预览功能。我可以在页面上立刻看到生成效果,所见即所得。这种直观的反馈让我能够快速调整,避免了反复修改的麻烦。细节里的用心除了基本功能,这个工具在细节处理上也让我印象深刻。它提供了强大的自定义功能。如果我有特殊的尺寸需求,可以直接输入数值添加自定义预设。更棒的是,我的自定义设置会自动保存到本地,下次访问时依然可用。这个小细节让我感觉非常贴心。一键打包下载功能也很实用。生成满意后,点击下载按钮就能获得包含所有尺寸图标的压缩包(ZIP格式)。文件结构清晰,文件名规范,直接拖入项目就能使用。不过,让我最满意的还是它的安全性。这个工具采用纯前端技术开发,所有图片处理都在我的浏览器本地完成,原图不会上传至服务器,彻底杜绝隐私泄露风险。对于我们开发者来说,这一点非常重要。适合谁用我觉得这个工具特别适合几类人群:独立开发者:快速生成上架所需的整套图标资源,节省时间和精力。UI/UX设计师:验证图标在不同尺寸下的显示效果,确保视觉一致性。网站站长:一键生成兼容性最好的Favicon,提升专业度。我自己作为独立开发者,每次新项目都会用它来生成图标。过去需要几个小时的工作,现在几分钟就能搞定,效率提升了很多。体验地址网站地址:http://ico.qmkj.top( 图标生成工具 )一点建议当然,任何工具都不是完美的。我觉得这个工具如果能加入更多自定义风格选项就更好了。比如支持一键生成不同风格的图标,或者提供一些设计模板,这样就能满足更多个性化需求。不过总体来说,这个工具已经相当不错了。它解决了图标制作的核心痛点,让开发者能够更专注于产品本身。如果你也经常被图标制作困扰,我推荐你试试这个免费、高效、安全的图标生成工具。相信它会像我一样,释放你的生产力。
这个图标工具,治好了我的选择困难症 这个图标工具,治好了我的选择困难症说起来,上周三下午在星巴克和几个朋友聊天,大家都在吐槽App图标制作的痛点。作为AI Native Coder,我对这个话题还挺有感触的。之前我写过一篇关于开发工具效率的文章,提到过在移动应用开发和网站建设过程中,图标制作往往是一个繁琐但必不可少的环节。不同的平台对图标的尺寸和格式都有着各自严格的要求,这让很多开发者头疼不已。我自己也深有体会。每次做新的项目,我都要花大量时间在图标上。从设计到导出不同尺寸的格式,再到适配各个平台,整个流程既繁琐又容易出错。最近我找到了一个不错的解决方案:一款在线的App图标/Favicon生成工具。我用了几次,感觉体验还不错。今天想分享一下我的使用感受。什么让我眼前一亮这个工具最吸引我的地方在于它对全平台的覆盖。我做项目经常要跨多个平台开发,需要制作不同尺寸的图标。这个工具内置了主流平台的标准图标尺寸预设,包括:iOS:iPhone, iPad, Apple Watch等全系列尺寸(20px - 1024px)。Android:适配各类分辨率屏幕的标准图标(36px - 512px)。微信小程序:覆盖小程序所需的各类图标尺寸。Web Favicon:自动生成适用于网站浏览器的.ico文件及多种PNG尺寸。这个数据还挺猛的,几乎涵盖了我平时用到的所有图标尺寸。之前我需要在PS里调整多个文件,现在只需上传一张高清原图,工具就能自动按照各平台规范进行裁剪和缩放。最让我惊喜的是实时预览功能。我可以在页面上立刻看到生成效果,所见即所得。这种直观的反馈让我能够快速调整,避免了反复修改的麻烦。细节里的用心除了基本功能,这个工具在细节处理上也让我印象深刻。它提供了强大的自定义功能。如果我有特殊的尺寸需求,可以直接输入数值添加自定义预设。更棒的是,我的自定义设置会自动保存到本地,下次访问时依然可用。这个小细节让我感觉非常贴心。一键打包下载功能也很实用。生成满意后,点击下载按钮就能获得包含所有尺寸图标的压缩包(ZIP格式)。文件结构清晰,文件名规范,直接拖入项目就能使用。不过,让我最满意的还是它的安全性。这个工具采用纯前端技术开发,所有图片处理都在我的浏览器本地完成,原图不会上传至服务器,彻底杜绝隐私泄露风险。对于我们开发者来说,这一点非常重要。适合谁用我觉得这个工具特别适合几类人群:独立开发者:快速生成上架所需的整套图标资源,节省时间和精力。UI/UX设计师:验证图标在不同尺寸下的显示效果,确保视觉一致性。网站站长:一键生成兼容性最好的Favicon,提升专业度。我自己作为独立开发者,每次新项目都会用它来生成图标。过去需要几个小时的工作,现在几分钟就能搞定,效率提升了很多。体验地址网站地址:http://ico.qmkj.top( 图标生成工具 )一点建议当然,任何工具都不是完美的。我觉得这个工具如果能加入更多自定义风格选项就更好了。比如支持一键生成不同风格的图标,或者提供一些设计模板,这样就能满足更多个性化需求。不过总体来说,这个工具已经相当不错了。它解决了图标制作的核心痛点,让开发者能够更专注于产品本身。如果你也经常被图标制作困扰,我推荐你试试这个免费、高效、安全的图标生成工具。相信它会像我一样,释放你的生产力。 -
Git修改文件按原目录结构复制——Windows下的最佳实践 引言在使用Git进行版本控制的开发过程中,有时我们需要将所有已修改但尚未提交的文件复制到另一个位置,同时保持原来的目录结构。这在诸多场景中非常有用:例如为变更创建备份、将修改的代码发送给同事审查、在不同环境中测试变更等。虽然这看似简单的需求,但在Windows系统中并没有一个直接的命令可以完成此操作。本文将详细介绍如何使用PowerShell脚本和批处理文件在Windows系统中高效地将Git已修改文件按原目录结构复制出来的方法。无论你是前端开发人员、后端开发人员,还是DevOps工程师,这些方法都能帮助你更高效地管理代码变更。基本概念在开始之前,让我们明确一下Git中几个重要的文件状态:已修改未暂存的文件:已修改但尚未执行git add命令的文件已暂存的文件:已执行git add命令但尚未提交的文件未跟踪的新文件:新增但未被Git跟踪的文件我们的目标是提供一种方法,能够将上述所有类型的文件按照它们在项目中的原始目录结构复制到指定目录。方案实现方案一:PowerShell直接执行命令最直接的方法是在PowerShell中执行以下命令:$TargetDir = "D:\您想要的目标目录"; if (-not (Test-Path -Path $TargetDir)) { New-Item -ItemType Directory -Path $TargetDir -Force | Out-Null; Write-Host "创建目标目录: $TargetDir" -ForegroundColor Green }; $modifiedFiles = git ls-files --modified; $stagedFiles = git diff --cached --name-only; $untrackedFiles = git ls-files --others --exclude-standard; $allChangedFiles = $modifiedFiles + $stagedFiles + $untrackedFiles | Sort-Object -Unique; $filesCopied = 0; foreach ($file in $allChangedFiles) { if (-not $file) { continue }; if (-not (Test-Path -Path $file)) { Write-Host "警告: 文件不存在: $file" -ForegroundColor Yellow; continue }; $destPath = Join-Path -Path $TargetDir -ChildPath $file; $destDir = Split-Path -Path $destPath -Parent; if (-not (Test-Path -Path $destDir)) { New-Item -ItemType Directory -Path $destDir -Force | Out-Null }; Copy-Item -Path $file -Destination $destPath -Force; Write-Host "已复制: $file" -ForegroundColor Cyan; $filesCopied++ }; Write-Host "`n完成! 共复制了 $filesCopied 个已更改的文件到 $TargetDir" -ForegroundColor Green这个命令执行以下操作:设置目标目录并确保它存在获取所有已修改、已暂存和未跟踪的文件列表遍历所有文件,创建必要的目录结构,并复制文件显示进度和结果信息这种方法的优点是不需要创建任何脚本文件,但缺点是命令较长,不便于记忆和重复使用。方案二:PowerShell脚本(需要修改执行策略)为了更方便地重复使用,我们可以创建PowerShell脚本文件。这里提供三个不同功能的脚本:1. 仅复制已修改未暂存的文件# 复制Git已修改文件脚本 # 使用方法: .\copy-modified-files.ps1 -TargetDir "D:\目标文件夹" param ( [Parameter(Mandatory=$true)] [string]$TargetDir ) # 确保目标目录存在 if (-not (Test-Path -Path $TargetDir)) { New-Item -ItemType Directory -Path $TargetDir -Force | Out-Null Write-Host "创建目标目录: $TargetDir" -ForegroundColor Green } # 获取git已修改文件列表 $modifiedFiles = git ls-files --modified $filesCopied = 0 foreach ($file in $modifiedFiles) { # 创建目标文件路径 $destPath = Join-Path -Path $TargetDir -ChildPath $file # 确保目标文件的父目录存在 $destDir = Split-Path -Path $destPath -Parent if (-not (Test-Path -Path $destDir)) { New-Item -ItemType Directory -Path $destDir -Force | Out-Null } # 复制文件 Copy-Item -Path $file -Destination $destPath -Force Write-Host "已复制: $file" -ForegroundColor Cyan $filesCopied++ } Write-Host "`n完成! 共复制了 $filesCopied 个已修改的文件到 $TargetDir" -ForegroundColor Green2. 复制已修改和已暂存的文件# 复制所有Git已修改文件脚本(包括已暂存和未暂存) # 使用方法: .\copy-all-modified-files.ps1 -TargetDir "D:\目标文件夹" param ( [Parameter(Mandatory=$true)] [string]$TargetDir ) # 确保目标目录存在 if (-not (Test-Path -Path $TargetDir)) { New-Item -ItemType Directory -Path $TargetDir -Force | Out-Null Write-Host "创建目标目录: $TargetDir" -ForegroundColor Green } # 获取已修改但未暂存的文件 $modifiedFiles = git ls-files --modified # 获取已暂存的文件 $stagedFiles = git diff --cached --name-only # 合并文件列表并去重 $allModifiedFiles = $modifiedFiles + $stagedFiles | Sort-Object -Unique $filesCopied = 0 foreach ($file in $allModifiedFiles) { # 创建目标文件路径 $destPath = Join-Path -Path $TargetDir -ChildPath $file # 确保目标文件的父目录存在 $destDir = Split-Path -Path $destPath -Parent if (-not (Test-Path -Path $destDir)) { New-Item -ItemType Directory -Path $destDir -Force | Out-Null } # 复制文件 Copy-Item -Path $file -Destination $destPath -Force Write-Host "已复制: $file" -ForegroundColor Cyan $filesCopied++ } Write-Host "`n完成! 共复制了 $filesCopied 个修改的文件到 $TargetDir" -ForegroundColor Green3. 复制所有变更(包括未跟踪的新文件)# 复制所有Git更改文件脚本(包括已修改、已暂存和未跟踪的新文件) # 使用方法: .\copy-all-git-changes.ps1 -TargetDir "D:\目标文件夹" param ( [Parameter(Mandatory=$true)] [string]$TargetDir ) # 确保目标目录存在 if (-not (Test-Path -Path $TargetDir)) { New-Item -ItemType Directory -Path $TargetDir -Force | Out-Null Write-Host "创建目标目录: $TargetDir" -ForegroundColor Green } # 获取已修改但未暂存的文件 $modifiedFiles = git ls-files --modified # 获取已暂存的文件 $stagedFiles = git diff --cached --name-only # 获取未跟踪的文件 $untrackedFiles = git ls-files --others --exclude-standard # 合并文件列表并去重 $allChangedFiles = $modifiedFiles + $stagedFiles + $untrackedFiles | Sort-Object -Unique $filesCopied = 0 foreach ($file in $allChangedFiles) { # 跳过空字符串(如果有) if (-not $file) { continue } # 确保文件存在 if (-not (Test-Path -Path $file)) { Write-Host "警告: 文件不存在: $file" -ForegroundColor Yellow continue } # 创建目标文件路径 $destPath = Join-Path -Path $TargetDir -ChildPath $file # 确保目标文件的父目录存在 $destDir = Split-Path -Path $destPath -Parent if (-not (Test-Path -Path $destDir)) { New-Item -ItemType Directory -Path $destDir -Force | Out-Null } # 复制文件 Copy-Item -Path $file -Destination $destPath -Force Write-Host "已复制: $file" -ForegroundColor Cyan $filesCopied++ } Write-Host "`n完成! 共复制了 $filesCopied 个已更改的文件到 $TargetDir" -ForegroundColor Green使用这些脚本前,需要临时修改PowerShell的执行策略:# 临时修改当前会话的执行策略 Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass # 然后运行脚本 .\copy-all-git-changes.ps1 -TargetDir "D:\您想要的目标目录"这种方法的优点是功能更丰富,可以根据需要选择不同的脚本;缺点是需要修改PowerShell的执行策略,这在某些环境中可能受到限制。方案三:批处理文件(推荐)为了避免修改PowerShell执行策略的问题,我们可以创建一个批处理文件来调用PowerShell命令:@echo off REM 复制Git已修改文件的批处理脚本 REM 使用方法: copy-git-changes.bat "D:\目标文件夹" IF "%~1"=="" ( echo 错误: 请提供目标目录路径 echo 用法: copy-git-changes.bat "D:\目标文件夹" exit /b 1 ) SET TargetDir=%~1 echo 正在复制Git中已修改的文件到 %TargetDir% ... powershell.exe -NoProfile -ExecutionPolicy Bypass -Command "$TargetDir = '%TargetDir%'; if (-not (Test-Path -Path $TargetDir)) { New-Item -ItemType Directory -Path $TargetDir -Force | Out-Null; Write-Host \"创建目标目录: $TargetDir\" -ForegroundColor Green }; $modifiedFiles = git ls-files --modified; $stagedFiles = git diff --cached --name-only; $untrackedFiles = git ls-files --others --exclude-standard; $allChangedFiles = $modifiedFiles + $stagedFiles + $untrackedFiles | Sort-Object -Unique; $filesCopied = 0; foreach ($file in $allChangedFiles) { if (-not $file) { continue }; if (-not (Test-Path -Path $file)) { Write-Host \"警告: 文件不存在: $file\" -ForegroundColor Yellow; continue }; $destPath = Join-Path -Path $TargetDir -ChildPath $file; $destDir = Split-Path -Path $destPath -Parent; if (-not (Test-Path -Path $destDir)) { New-Item -ItemType Directory -Path $destDir -Force | Out-Null }; Copy-Item -Path $file -Destination $destPath -Force; Write-Host \"已复制: $file\" -ForegroundColor Cyan; $filesCopied++ }; Write-Host \"`n完成! 共复制了 $filesCopied 个已更改的文件到 $TargetDir\" -ForegroundColor Green" echo 操作完成!使用方法:.\copy-git-changes.bat "D:\您想要的目标目录"这种方法的优点是:不需要修改任何系统安全设置使用简单,只需要运行批处理文件并指定目标目录可以永久保存批处理文件以便将来使用自动创建必要的目录结构并保持原目录结构工作原理解析这些脚本的工作原理是利用Git提供的命令来获取不同状态的文件列表:git ls-files --modified:获取已修改但未暂存的文件git diff --cached --name-only:获取已暂存但未提交的文件git ls-files --others --exclude-standard:获取未跟踪的新文件然后,脚本将这些文件列表合并并去重,接着遍历每个文件并将其复制到目标目录中的相应位置,同时保持原目录结构。实际应用场景代码备份:在进行大型重构前备份已修改的文件问题排查:将修改过的文件复制到测试环境进行问题复现代码审查:将修改的文件提供给同事进行离线审查环境迁移:在不同环境间转移尚未提交的变更增量部署:仅部署已修改的文件到服务器常见问题与解决方案PowerShell脚本无法执行问题:执行PowerShell脚本时提示"在此系统上禁止运行脚本"。解决方案:使用批处理文件方法(方案三)或临时修改执行策略:Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass某些文件未被复制问题:部分文件未被复制到目标目录。解决方案:确保文件已被Git识别(已修改、已暂存或未跟踪)对于二进制文件或符号链接,可能需要特殊处理检查文件是否被.gitignore忽略目录结构不正确问题:目标目录中的文件结构与原项目不一致。解决方案:确保在项目根目录运行脚本检查脚本中的路径处理逻辑总结在Windows系统中将Git已修改的文件按原目录结构复制出来有多种方法,其中使用批处理文件的方法(方案三)最为推荐,因为它不需要修改任何系统设置,使用简单,并且可以永久保存以便将来使用。通过本文介绍的方法,你可以轻松地将Git中已修改、已暂存和未跟踪的文件复制到指定目录,同时保持原目录结构,这对于代码备份、问题排查、代码审查等场景非常有用。希望这篇文章能够帮助你更高效地管理代码变更。如果你有任何问题或建议,欢迎在评论区留言。参考资料Git官方文档 - git-ls-filesPowerShell官方文档 - Copy-ItemWindows批处理脚本教程
-
同事看了想打人!这8个SQL写法让数据库慢到崩溃 坑点1:翻页越往后越卡当你用LIMIT 1000000,10查数据时,数据库就像翻一本100万页的书——明明只要第100万页的10行字,却得从第一页开始数。优化大招:记住上次看到哪儿。比如上次翻页最后一条的创建时间是"2023-01-01 12:00:00",下页查询直接加条件WHERE create_time > '2023-01-01 12:00:00',秒出结果。问题案例:-- 传统分页(偏移量越大性能越差) SELECT * FROM logs WHERE log_type='ERROR' ORDER BY create_time LIMIT 1000000, 10; -- 需遍历前100万条记录优化方案:-- 游标分页法(基于最后时间戳) SELECT * FROM logs WHERE log_type='ERROR' AND create_time > '2024-02-17 00:00:00' -- 使用上一页末尾时间 ORDER BY create_time LIMIT 10; -- 执行时间稳定在5ms内坑点2:乱填参数害死索引字段明明是varchar类型,程序却传了数字进来。这就好比用家门钥匙开汽车锁,数据库只能暴力拆锁全表扫描。检查方法:执行SHOW WARNINGS看到类型转换警告,赶紧让程序员改代码对齐类型。问题案例:-- 字段phone定义为VARCHAR(20),但传入数值参数 SELECT * FROM users WHERE phone = 13800138000; -- 触发类型转换,索引失效 -- 查看执行计划警告 SHOW WARNINGS; > Warning: Cannot use ref access on index 'phone' due to type conversion 优化方案:-- 添加引号保持类型一致 SELECT * FROM users WHERE phone = '13800138000'; -- 正确使用索引坑点3:更新语句慢如蜗牛用UPDATE...WHERE id IN (子查询)更新数据?MySQL会傻乎乎地循环查几千次。救星方案:改成JOIN写法,让数据库一次性关联更新。实测有个案例从7秒降到2毫秒。问题案例:-- 错误写法(嵌套子查询) UPDATE orders o SET status = 'expired' WHERE o.id IN ( SELECT id FROM ( SELECT id FROM orders WHERE create_time < '2023-01-01' LIMIT 1000 ) tmp ); -- 执行时间>10秒优化方案:-- 改用JOIN重写 UPDATE orders o JOIN ( SELECT id FROM orders WHERE create_time < '2023-01-01' LIMIT 1000 ) tmp ON o.id = tmp.id SET status = 'expired'; -- 执行时间<100ms坑点4:混搭排序逼疯数据库 既要按评分升序,又要按时间降序,索引直接罢工。破解术:拆成两次查询再合并。比如先查未回复的订单按时间排序,再查已回复的,最后拼起来。问题案例:-- 混合排序导致全表扫描 SELECT * FROM product_reviews ORDER BY is_approved ASC, review_time DESC LIMIT 20; -- 无法使用(is_approved,review_time)索引优化方案:-- 拆分查询+UNION ALL (SELECT * FROM product_reviews WHERE is_approved=0 ORDER BY review_time DESC LIMIT 20) UNION ALL (SELECT * FROM product_reviews WHERE is_approved=1 ORDER BY review_time DESC LIMIT 20) ORDER BY is_approved ASC, review_time DESC LIMIT 20; -- 执行效率提升80倍坑点5:乱用SELECT * 拖垮网络动不动就SELECT *,把不要的字段也查出来。特别是text大字段,传输速度直接腰斩。保命原则:需要什么字段就写什么,别让数据库做快递小哥送垃圾。问题案例:-- 低效写法 SELECT * FROM employees e WHERE EXISTS ( SELECT 1 FROM salaries s WHERE s.emp_id = e.id AND s.year = 2023 ); -- 嵌套循环执行优化方案:-- 改用JOIN优化 SELECT e.* FROM employees e INNER JOIN salaries s ON e.id = s.emp_id AND s.year = 2023; -- 利用索引快速定位坑点6:模糊搜索堵死CPULIKE '%关键字%'这种查询,数据库只能玩命扫描。应急方案:上Elasticsearch做专业搜索,或者业务上限制必须带前缀查询。问题案例:-- 用户搜索包含"error"的日志(无前缀模糊匹配) SELECT * FROM server_logs WHERE log_message LIKE '%error%'; -- 执行计划:全表扫描,耗时12秒(数据量500万行)优化方案:-- 方案1:强制前缀匹配(利用索引) SELECT * FROM server_logs WHERE log_message LIKE 'error%'; -- 使用前缀索引 -- 方案2:集成Elasticsearch(专业分词检索) PUT /logs/_search { "query": { "match": { "message": "error" } } }原理说明: B+树索引无法逆向检索,LIKE '%xx'会导致索引失效。前缀匹配可触发索引范围扫描,而全文检索场景建议使用专用引擎(如ES)的分词能力。坑点7:乱堆OR条件让索引哭晕WHERE a=1 OR b=2这种写法,数据库往往直接放弃治疗全表扫描。改造技巧:拆成两个查询用UNION合并,速度提升50倍。问题案例:-- 查询订单状态为"paid"或物流单号为"SF123"的订单 SELECT * FROM orders WHERE status = 'paid' OR tracking_no = 'SF123'; -- 执行计划:全表扫描,耗时8秒(数据量200万行)优化方案:-- 拆分为UNION查询(分别利用不同索引) (SELECT * FROM orders WHERE status = 'paid') UNION (SELECT * FROM orders WHERE tracking_no = 'SF123'); -- 执行时间:0.2秒(提升40倍)原理说明: OR条件导致优化器无法选择有效索引。拆分为UNION后,可分别利用status和tracking_no的单列索引,再合并结果集。坑点8:子查询嵌套套到死在WHERE里疯狂嵌套子查询,MySQL会被逼成单线程工人。优化真经:多用临时表或JOIN代替,给数据库留条活路。问题案例:-- 查询有评论的商品(嵌套子查询) SELECT * FROM products WHERE id IN ( SELECT product_id FROM comments WHERE create_time > '2024-01-01' ); -- 执行计划:DEPENDENT SUBQUERY,耗时15秒 优化方案:-- 方案1:改用JOIN关联(触发索引嵌套循环) SELECT p.* FROM products p JOIN comments c ON p.id = c.product_id WHERE c.create_time > '2024-01-01'; -- 方案2:临时表预存子查询结果 CREATE TEMPORARY TABLE tmp_products AS SELECT product_id FROM comments WHERE create_time > '2024-01-01'; SELECT p.* FROM products p JOIN tmp_products t ON p.id = t.product_id; -- 执行时间均降至0.5秒内 原理说明: 嵌套子查询会导致循环执行,而JOIN或临时表可将多次查询优化为单次数据关联。通过执行计划分析,JOIN写法通常能触发更优的Index Nested-Loop Join算法。看完赶紧检查下自己写的SQL,别让同事半夜打电话骂人!遇到过更奇葩SQL坑货的,欢迎留言区吐槽才哥最近开发了一个针对Java开发人员的面试刷题小程序,计划准备面试的伙伴们可以去试试,手机在线刷题更方便
-
Java的泛型应用与了解 Java泛型的功能主要是在编译阶段进行类型安全的检查,让开发者能够编写出更具通用性和灵活性的代码,有效避免在程序运行过程中出现类型转换的错误。泛型的作用:确保类型安全:泛型能够在编译时进行严格的类型检查,确保在操作集合或其他泛型类时,不会出现类型不一致的情况,从而降低运行时出现ClassCastException异常的风险。提升代码复用性:借助泛型,代码可以适用于多种不同的数据类型,减少了代码的重复编写,使得代码的可读性和可维护性得到提升。避免显式类型转换:通过在编译时明确指定类型参数,泛型省去了在运行时进行显式类型转换的步骤,简化了代码的编写。示例代码:List<String> stringList = new ArrayList<>(); stringList.add("Hello"); String message = stringList.get(0); // 无需进行类型转换泛型的实际应用场景集合框架中的应用:Java的集合框架大量运用了泛型。像List<T>、Set<T>以及Map<K, V>等接口,能够针对不同的数据类型实现统一的操作方式。泛型方法的定义:不仅可以定义泛型类,还可以定义泛型方法,这样可以使方法具备处理多种不同数据类型的能力。例如:public static <T> void printElements(T[] elements) { for (T element : elements) { System.out.println(element); } }为何需要泛型的通俗解释在Java 5版本之前,泛型是不存在的,那时的代码也能正常运行,那么为何要引入泛型呢,它能为我们带来哪些好处呢?先来看下面这段代码:List list = new ArrayList(); list.add("yes"); // 添加字符串 list.add(233); // 添加整数在没有泛型的时期,集合中添加的数据不会受到任何类型限制,全部被视为Object类型。或许有人会觉得这样很自由,确实,自由度很高,但是代码的约束性越弱,出错的概率就越高,在使用上也会带来诸多不便,比如在获取数据时需要进行强制类型转换。如果一不小心获取了错误的类型,虽然代码能够通过编译,但在运行时却会抛出异常。综上所述,Java引入了泛型机制。泛型的作用就是增加了一层类型约束。有了这层约束,由于已经声明了类型,所以在编译阶段就能识别出不准确的类型元素。这样可以让错误提前被发现,避免在运行时才暴露出来。并且也不需要在代码中显式地进行强制类型转换,从下面的代码可以看出,可以直接获取到String类型的元素。我们再总结一下泛型的优势:提升了代码的可读性,能够一眼看出集合(或其他泛型类)所存储的数据类型能在编译阶段检查类型安全,增强程序的健壮性省去了显式类型转换的麻烦(实际上内部已经完成了类型转换)提高了代码的复用性,定义好的泛型可以让一个方法(或类)适用于所有类型(虽然以前使用Object也可以实现,但相对较为繁琐)为何有人说Java的泛型是伪泛型来看下面这段代码:可以看到,虽然声明的是一个String类型的集合,但通过反射的方式却能够成功地向集合中插入int类型的数据。这表明在运行时,泛型并没有起到任何作用!也就是说,在运行过程中,JVM无法获取到泛型的信息,也不会对其进行任何约束。可以认为Java的泛型仅在编译时有效,而在运行时则不存在泛型,这也是人们常说Java是伪泛型的原因。简而言之,Java的泛型仅在编译阶段发挥作用,而在JVM运行时则不存在泛型的概念。近期才哥整理出了一个可用于快速刷面试题的小程序,其中收录了常见面试题及其答案,涵盖了基础、并发、JVM、MySQL、Redis、Spring、SpringMVC、SpringBoot、SpringCloud、消息队列等多个类型,感兴趣的扫下方的小程序码进行体验。
-
Java 插件模式SPI学习与理解(Java SPI 、Spring SPI、Dubbo SPI) SPI 全称为 Service Provider Interface,是一种服务发现机制,其核心在于将接口实现类的全限定名配置在文件中,由服务加载器读取并加载实现类,从而可在运行时为接口动态替换实现类,为程序提供拓展功能。1. 重新阐述 Java SPI 示例定义接口和实现类:首先定义一个名为 Robot 的接口,包含 sayHello 方法。public interface Robot { void sayHello(); } 然后创建两个实现类 OptimusPrime 和 Bumblebee,它们都实现了 Robot 接口并实现了 sayHello 方法。 public class OptimusPrime implements Robot { @Override public void sayHello() { System.out.println("Hello, I am Optimus Prime."); } } public class Bumblebee implements Robot { @Override public void sayHello() { System.out.println("Hello, I am Bumblebee."); } } 配置文件:在 META-INF/services 文件夹下创建名为 org.apache.spi.Robot 的文件(这里假设接口全限定名为 org.apache.spi.Robot),文件内容包含实现类的全限定名: org.apache.spi.OptimusPrime org.apache.spi.Bumblebee 测试代码: public class JavaSPITest { @Test public void sayHello() throws Exception { ServiceLoader<Robot> serviceLoader = ServiceLoader.load(Robot.class); System.out.println("Java SPI"); // 两种遍历模式 serviceLoader.forEach(Robot::sayHello); Iterator<Robot> iterator = serviceLoader.iterator(); while (iterator.hasNext()) { Robot robot = iterator.next(); // 可以调用 robot.sayHello() 进行测试 } } } 2. 经典 Java SPI 应用:JDBC DriverManager传统 JDBC 驱动加载:在 JDBC4.0 之前,需要先使用 Class.forName("com.mysql.jdbc.Driver") 加载数据库驱动,然后进行连接操作。 // STEP 1: Register JDBC driver Class.forName("com.mysql.jdbc.Driver"); // STEP 2: Open a connection String url = "jdbc:xxxx://xxxx:xxxx/xxxx"; Connection conn = DriverManager.getConnection(url,username,password); 使用 SPI 后的 JDBC 驱动加载:JDBC4.0 之后利用 Java 的 SPI 扩展机制,无需手动调用 Class.forName 加载驱动,可直接获取连接。DriverManager 类是驱动管理器,在其静态初始化块中调用 loadInitialDrivers 方法,其中涉及 SPI 的使用: static { loadInitialDrivers(); println("JDBC DriverManager initialized"); } 加载驱动的四个步骤:从系统变量获取驱动定义。用 SPI 获取驱动实现类(字符串形式)。ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class); 遍历使用 SPI 获取的实现,实例化各实现类。 Iterator<Driver> driversIterator = loadedDrivers.iterator(); while(driversIterator.hasNext()) { driversIterator.next(); } 根据第一步的驱动列表实例化具体实现类。3. Java SPI 机制源码解析ServiceLoader 类的 load 方法:public static <S> ServiceLoader<S> load(Class<S> service) { ClassLoader cl = Thread.currentThread().getContextClassLoader(); return ServiceLoader.load(service, cl); } public static <S> ServiceLoader<S> load(Class<S> service, ClassLoader loader) { return new ServiceLoader<>(service, loader); } 该方法根据服务类型和类加载器创建 ServiceLoader 对象。- `ServiceLoader` 构造器:private ServiceLoader(Class<S> svc, ClassLoader cl) { service = Objects.requireNonNull(svc, "Service interface cannot be null"); loader = (cl == null)? ClassLoader.getSystemClassLoader() : cl; acc = (System.getSecurityManager()!= null)? AccessController.getContext() : null; reload(); } private LinkedHashMap<String,S> providers = new LinkedHashMap<>(); public void reload() { providers.clear(); lookupIterator = new LazyIterator(service, loader); } 私有构造器创建懒迭代器 LazyIterator 对象,只有调用迭代方法时才执行加载逻辑。迭代器的 hasNext() 方法: public boolean hasNext() { if (acc == null) { return hasNextService(); } else { PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() { public Boolean run() { return hasNextService(); } }; return AccessController.doPrivileged(action, acc); } } 该方法最终调用 hasNextService 方法,会通过加载器获取配置对象并解析 META-INF/services/ 目录下的文件。迭代器的 next() 方法: public S next() { if (acc == null) { return nextService(); } else { PrivilegedAction<S> action = new PrivilegedAction<S>() { public S run() { return nextService(); } }; return AccessController.doPrivileged(action, acc); } } 本质是调用 nextService 方法,通过反射加载类对象,实例化类并缓存到 providers 对象中。4. Java SPI 机制的缺陷无法按需加载,会遍历并实例化所有实现,即使部分实现类不需要或实例化耗时。获取实现类的方式仅能通过 Iterator,不够灵活,不能根据参数获取特定实现类。多线程使用 ServiceLoader 实例时不安全。5. Spring SPI 机制创建接口和实现类:定义 MyTestService 接口: public interface MyTestService { void printMylife(); } 创建实现类 WorkTestService 和 FamilyTestService: public class WorkTestService implements MyTestService { public WorkTestService(){ System.out.println("WorkTestService"); } public void printMylife() { System.out.println("我的工作"); } } public class FamilyTestService implements MyTestService { public FamilyTestService(){ System.out.println("FamilyTestService"); } public void printMylife() { System.out.println("我的家庭"); } } 配置文件:在 META-INF/spring.factories 中配置接口和实现类:com.courage.platform.sms.demo.service.MyTestService = com.courage.platform.sms.demo.service.impl.FamilyTestService,com.courage.platform.sms.demo.service.impl.WorkTestService 测试代码: List<MyTestService> myTestServices = SpringFactoriesLoader.loadFactories( MyTestService.class, Thread.currentThread().getContextClassLoader() ); for (MyTestService testService : myTestServices) { testService.printMylife(); } 与 Java SPI 的区别:Java SPI 一个服务接口对应一个配置文件,Spring SPI 一个 spring.factories 配置文件存放多个接口及实现类,以接口全限定名作为 key,实现类作为 value,多个实现类用逗号分隔。两者都无法获取特定的实现,只能按顺序获取所有实现。6. Dubbo SPI 机制配置文件:配置文件放在 META-INF/dubbo 路径下,以键值对方式配置实现类: optimusPrime = org.apache.spi.OptimusPrime bumblebee = org.apache.spi.Bumblebee 测试代码: public class DubboSPITest { @Test public void sayHello() throws Exception { ExtensionLoader<Robot> extensionLoader = ExtensionLoader.getExtensionLoader(Robot.class); Robot optimusPrime = extensionLoader.getExtension("optimusPrime"); optimusPrime.sayHello(); Robot bumblebee = extensionLoader.getExtension("bumblebee"); bumblebee.sayHello(); } } 特点:支持按需加载接口实现类,可通过键值对方式指定要加载的实现。相比 Java SPI 增加了 IOC 和 AOP 等特性。近期才哥整理出了一个可用于快速刷面试题的小程序,其中收录了常见面试题及其答案,涵盖了基础、并发、JVM、MySQL、Redis、Spring、SpringMVC、SpringBoot、SpringCloud、消息队列等多个类型,感兴趣的可以点击下方试试。